

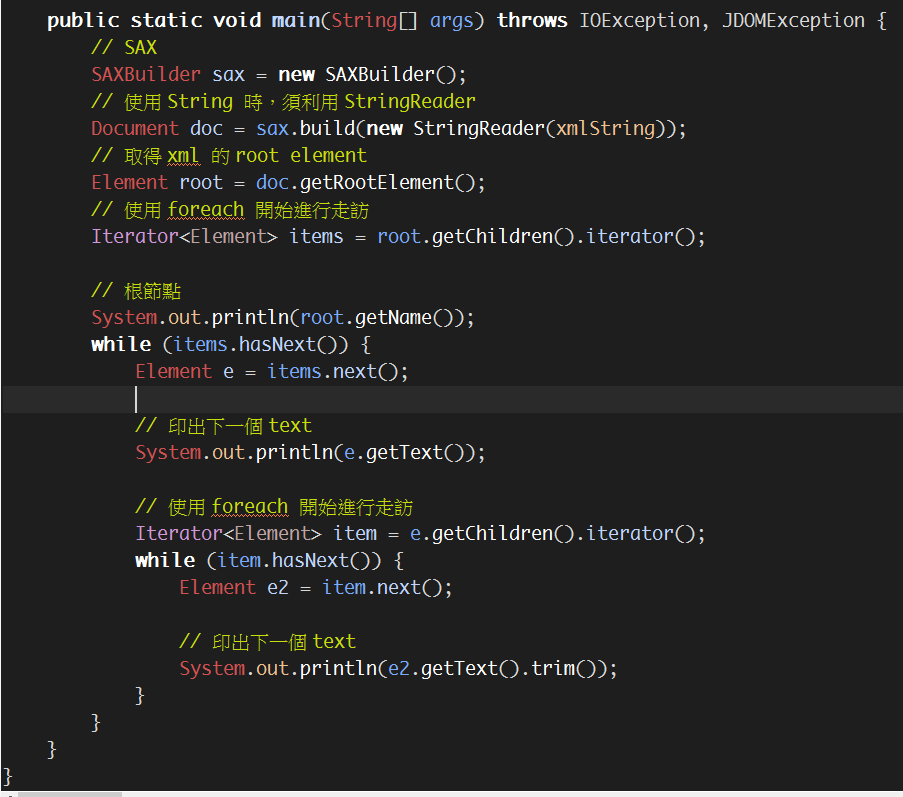
// SAX
SAXBuilder sax = new SAXBuilder();
// 使用 String 時,須利用 StringReader
Document doc = sax.build(new StringReader(xmlString));
// 取得 xml 的 root element
Element root = doc.getRootElement();
// 使用 foreach 開始進行走訪
Iterator<Element> items = root.getChildren().iterator();
// 根節點
System.out.println(root.getName());
while (items.hasNext()) {
Element e = items.next();
// 印出下一個 text
System.out.println(e.getText());
// 使用 foreach 開始進行走訪
Iterator<Element> item = e.getChildren().iterator();
while (item.hasNext()) {
Element e2 = item.next();
// 印出下一個 text
System.out.println(e2.getText().trim());
}
}
}




